Table of Contents
젬마 4는 “또 하나의 오픈 모델” 정도로 보면 아쉬운 발표입니다. 구글이 2026년 4월 2일 공개한 젬마 4는 단순히 작은 모델을 추가한 수준이 아니라, 온디바이스 AI와 에이전트형 워크플로를 더 현실적인 영역으로 끌어오겠다는 선언에 가깝습니다. 특히 로컬 실행, 상업적 활용, 긴 컨텍스트, 멀티모달 입력을 한 번에 묶었다는 점이 눈에 띕니다.
국내에서도 반응은 뜨겁습니다. 2026년 4월 3일 조선비즈 등 한국 매체가 바로 젬마 4를 다뤘고, 보도 포인트도 비슷했습니다. “왜 지금 이 모델이 중요하냐”를 한 줄로 요약하면, 클라우드 API만 쓰는 시대에서 벗어나 기기 안에서 직접 돌리고, 필요하면 기업이 직접 통제할 수 있는 AI 수요가 커지고 있기 때문입니다.
젬마 4는 무엇이고 왜 지금 봐야 할까
젬마 4는 구글 딥마인드가 공개한 오픈 모델 계열의 최신 버전입니다. 구글 공식 블로그에 따르면 이번 세대는 제미나이 3와 같은 연구 기반 위에서 만들어졌고, 고급 추론과 에이전트 워크플로를 염두에 두고 설계됐습니다. 쉽게 말하면 “작지만 쓸 만한 오픈 모델”에서 한 단계 더 나아가 “로컬과 제품 환경에 실제로 넣어볼 수 있는 오픈 모델”로 방향을 선명하게 잡은 셈입니다.
여기서 중요한 건 젬마 4가 제미나이의 대체재가 아니라는 점입니다. 구글도 공식 발표에서 젬마와 제미나이를 상호 보완 관계로 설명합니다. 제미나이가 강력한 폐쇄형 상용 모델 라인업이라면, 젬마 4는 개발자와 기업이 직접 수정하고 배포하고 통제하기 쉬운 오픈 쪽 카드입니다. 데이터 통제, 배포 유연성, 로컬 실행, 비용 최적화가 중요하면 젬마 4 쪽이 더 매력적일 수 있습니다.
- 공개 시점: 2026년 4월 2일
- 라이선스: Apache 2.0
- 핵심 방향: 추론, 코딩, 에이전트 워크플로, 온디바이스 실행
- 지원 범위: 140개 이상 언어, 최대 256K 컨텍스트
젬마 4에서 실제로 달라진 점
이번 세대에서 먼저 볼 부분은 모델 구성이 훨씬 선명해졌다는 점입니다. 젬마 4는 E2B, E4B, 26B A4B MoE, 31B Dense 네 가지로 나왔습니다. 작은 모델은 모바일과 엣지 기기, 큰 모델은 워크스테이션이나 서버 쪽을 겨냥합니다. 즉 “한 모델로 다 해결”이 아니라 하드웨어 조건에 맞춰 가져다 쓰기 쉽게 짜인 제품군입니다.
기능 측면에서는 단순 대화형 모델에서 더 멀리 갔습니다. 공식 자료 기준으로 젬마 4는 추론 모드, 함수 호출, 시스템 프롬프트, 긴 컨텍스트, 이미지 이해, 일부 모델의 오디오 입력까지 지원합니다. 특히 소형 모델인 E2B와 E4B가 오디오 입력을 지원하고, 더 큰 26B A4B와 31B는 텍스트와 이미지 중심으로 가는 구성이어서 용도 구분이 비교적 명확합니다.
- 26B A4B MoE – 총 파라미터는 26B급인데 활성 파라미터가 약 4B급
- E2B/E4B = 실효 파라미터 기준 약 2B / 4B
- 모델 크기: E2B, E4B, 26B A4B MoE, 31B Dense
- 컨텍스트 길이: E2B·E4B는 128K, 26B A4B·31B는 256K
- 멀티모달: 전 모델 텍스트·이미지, 소형 모델 한정 오디오까지 지원(아래 사진 참고)
- 에이전트 기능: 함수 호출, 구조화된 도구 사용, 시스템 지시문 지원

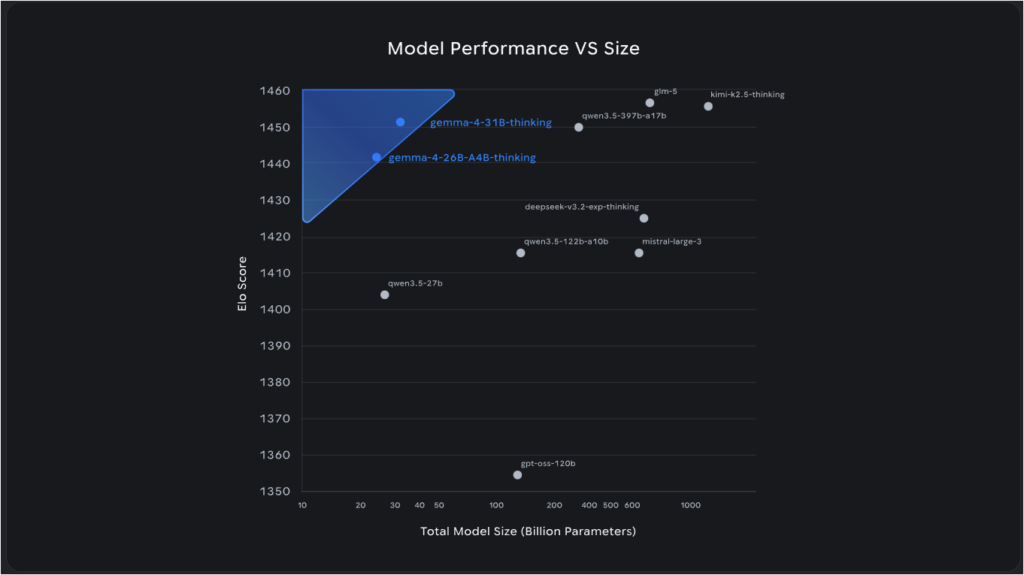
구글은 성능 면에서도 강하게 밀고 있습니다. 공식 발표에서는 31B 모델이 2026년 4월 1일 기준 Arena 계열 텍스트 리더보드에서 오픈 모델 3위, 26B 모델이 6위라고 설명했습니다. 다만 이런 순위는 언제든 바뀔 수 있으니, 순위 자체보다 “비슷한 목적의 더 큰 모델과 경쟁 가능한 수준을 작은 하드웨어 부담으로 노린다”는 방향을 읽는 편이 더 실용적입니다.
누가 젬마 4를 써볼 만할까
젬마 4는 모든 사람을 위한 모델은 아닙니다. 대신 맞는 사람에게는 꽤 설득력이 있습니다. 첫째, 데이터가 외부 API 서버를 계속 오가면 곤란한 팀입니다. 둘째, 모바일이나 엣지 기기에서 AI를 직접 돌리고 싶은 팀입니다. 셋째, 특정 도메인에 맞춰 파인튜닝하거나 로컬 도구 호출 흐름을 붙이고 싶은 개발 조직입니다.
안드로이드 개발자라면 더 직접적인 의미가 있습니다. 안드로이드 개발자 블로그에 따르면 젬마 4는 AICore Developer Preview로 미리 접근할 수 있고, 지금 작성한 코드가 이후 등장할 Gemini Nano 4 지원 기기와도 이어질 수 있게 설계됐습니다. 온디바이스 AI를 염두에 둔 앱 팀이라면 “나중에 보자”보다 “지금 프로토타입을 해볼 만하다”에 가깝습니다.
- 잘 맞는 경우: 로컬 실행, 데이터 통제, 온디바이스 AI, 커스텀 배포가 중요한 팀
- 애매한 경우: 그냥 바로 쓰는 챗봇 SaaS가 필요한 일반 사용자
- 특히 유리한 경우: 안드로이드 앱, 엣지 기기, 로컬 코드 보조, 내부 문서 처리
젬마 4 가격과 비용 구조는 어떻게 봐야 할까
여기서 많이 헷갈립니다. 젬마 4는 챗GPT나 제미나이 앱처럼 “월 얼마”로 끊어지는 서비스가 아닙니다. 모델 가중치가 Apache 2.0 라이선스로 공개된 오픈 모델이기 때문에, 핵심은 라이선스 비용보다 운영 비용입니다. 다시 말해 “젬마 4 자체 가격”보다 “어디서 어떻게 돌릴 것이냐”가 더 중요합니다.
가볍게 체험하는 시작점은 여러 개 있습니다. 구글 공식 발표 기준으로 31B와 26B MoE는 Google AI Studio에서, E2B와 E4B는 AI Edge Gallery 경로에서 빠르게 만져볼 수 있습니다. 또 Hugging Face, Kaggle, Ollama 등으로 가중치를 받아 직접 돌릴 수도 있습니다. 하지만 실제 제품 운영으로 가면 GPU, 모바일 칩셋, 서버 비용, 추론 최적화, 배포 관리가 비용의 본체가 됩니다.
- 라이선스 비용: Apache 2.0 기반이라 상업적 활용 장벽이 낮은 편
- 실제 비용: GPU·클라우드·모바일 칩·배포 방식에 따라 달라짐
- 빠른 체험: AI Studio, AI Edge Gallery, AICore Developer Preview
- 판단 포인트: 구독료보다 총소유비용(TCO)과 운영 난이도
젬마 4의 장점과 한계
장점
- 오픈 모델이면서도 최근 세대 기준으로 꽤 공격적인 성능을 노립니다.
- 소형 모델부터 31B급까지 라인업이 나뉘어 있어 하드웨어 선택 폭이 넓습니다.
- 함수 호출, 시스템 프롬프트, 긴 컨텍스트 같은 제품형 기능이 비교적 잘 갖춰졌습니다.
- 온디바이스와 엣지 시나리오가 분명해 모바일·IoT 팀에게 활용 명분이 있습니다.
- Apache 2.0 라이선스라 상업 적용과 내부 통제가 쉬운 편입니다.
한계
- “설치하면 끝”인 소비자용 서비스가 아니라서 운영 역량이 필요합니다.
- 대형 모델은 여전히 하드웨어 부담이 적지 않습니다.
- 모든 기능이 모든 크기에서 동일하지 않아 모델 선택을 잘못하면 기대와 달라질 수 있습니다.
- 공식 성능 수치는 인상적이지만 실제 업무 적합성은 데이터와 워크플로에 따라 달라집니다.
- 비용 구조가 정액제가 아니어서 팀에 따라 오히려 복잡할 수 있습니다.

제미나이와는 어떻게 다르게 봐야 하나
젬마 4를 제미나이의 “무료판”이나 “축소판”처럼 보면 판단이 흐려집니다. 제미나이는 구글이 서비스 품질과 운영을 직접 책임지는 상용 모델 축에 가깝고, 젬마 4는 개발자가 직접 가져가 조정하고 배포하는 오픈 모델 축에 가깝습니다. 그래서 비교 기준도 다릅니다.
빠르게 성능 좋은 API를 붙여 서비스만 만들고 싶다면 제미나이 쪽이 단순할 수 있습니다. 반대로 내부 배포, 오프라인 처리, 기기 내 실행, 모델 커스터마이징, 데이터 주권이 중요하면 젬마 4가 더 매력적입니다. 결국 “무엇이 더 좋냐”보다 “어떤 통제권이 필요하냐”가 기준입니다.
젬마 4 FAQ
젬마 4는 무료인가요?
모델 자체는 Apache 2.0 라이선스로 공개됐지만, 실제 사용 비용이 0원이라는 뜻은 아닙니다. 로컬 장비, 클라우드 GPU, 추론 최적화, 저장소와 운영 인력까지 합치면 비용 구조는 환경마다 달라집니다.
젬마 4는 일반 사용자도 바로 쓰기 쉬운가요?
완성형 챗봇 앱을 기대하면 조금 다릅니다. 젬마 4는 개발자와 제품 팀이 직접 실험하고 통합하기 좋은 모델에 가깝습니다. 다만 AI Studio, AI Edge Gallery, Ollama 같은 경로 덕분에 예전 오픈 모델보다 첫 체험 진입장벽은 낮아졌습니다.
젬마 4의 핵심 매력은 무엇인가요?
작은 하드웨어에서도 돌릴 수 있는 효율성과, 오픈 모델인데도 에이전트형 기능과 긴 컨텍스트를 함께 가져간 점입니다. 특히 온디바이스나 로컬 AI가 필요한 팀에게는 “성능 대비 통제권”이 가장 큰 장점입니다.
젬마 4는 한국어에도 쓸 만한가요?
구글 공식 자료 기준으로 140개 이상 언어를 학습했고, 멀티링구얼 활용을 전제로 설계됐습니다. 다만 실제 한국어 품질은 용도별 테스트가 필요합니다. 고객 응대, 문서 요약, 코드 보조, OCR 후처리처럼 목적을 나눠 검증하는 편이 안전합니다.
결론
젬마 4는 “오픈 모델도 이제 진짜 제품 후보로 볼 만하다”는 신호에 가깝습니다. 구글이 이번에 보여준 건 단순한 스펙 경쟁보다, 모바일·엣지·로컬 실행과 에이전트 워크플로를 한 묶음으로 밀어붙이는 전략입니다. 그래서 이 모델의 가치는 벤치마크 숫자보다도, 누가 얼마나 빠르게 자기 환경에 맞게 가져다 쓸 수 있느냐에서 갈릴 가능성이 큽니다.
정리하면, API 하나 붙여 바로 서비스하고 싶은 팀보다 데이터 통제, 온디바이스, 커스텀 배포가 중요한 팀이 먼저 봐야 할 모델입니다. 그런 조건에 해당한다면 젬마 4는 2026년 4월 기준 꽤 진지하게 테스트할 만한 카드입니다.
ai모아 에디터의 시선: 젬마 4는 “오픈이라 좋다”보다 “내 환경에서 통제 가능한 AI가 필요하다”는 팀에 더 정확히 맞는 모델입니다. 가볍게 구경할 대상이라기보다, 로컬 실행과 제품 내장 가능성을 따지는 사람에게 실익이 큰 발표로 보입니다.
👉 쉽게 이해하는 젬마 4 구조 (Dense vs MoE)
일반 모델(Dense)은 쉽게 말해 뇌를 전부 다 쓰는 방식입니다.
예를 들어 뇌가 26개 있으면, 매번 26개를 전부 동시에 사용합니다.
그래서 구조가 단순하지만, 상대적으로 무겁고 느릴 수 있습니다.
반면 젬마 4 같은 MoE 모델은 방식이 다릅니다.
뇌가 128개나 있지만, 매번 전부 쓰는 게 아니라 그중 필요한 일부만 골라서 사용합니다.
(정확히는 128개 중 일부 + 항상 같이 쓰는 기본 뇌 1개)
그래서 훨씬 가볍고 빠르게 동작하면서도, 상황에 따라 적절한 조합을 선택할 수 있습니다.
이걸 숫자로 보면 이렇게 이해하면 쉽습니다.
26B A4B 모델은 총 약 260억 개 규모의 파라미터를 가지고 있지만, 실제 계산에 사용하는 건 약 40억 개 수준입니다.
👉 즉, “큰 뇌를 가지고 있지만, 필요할 때 일부만 골라 쓰는 구조”라고 보면 됩니다.
요금제, 기능, 지원 범위는 수시로 바뀔 수 있으니 최신 내용은 공식 페이지 기준으로 확인해 주세요.
참고한 자료 : Gemma 4 공식 발표
더 많은 AI 툴 정보는 ai모아에서 확인하세요.
구글의 제미나이의 모아 스코어가 궁금하다면? -> 제미나이 모아 스코어 보러가기