Table of Contents
무료로 로컬에서 돌릴 수 있는 AI 모델이 나왔다고 해서 직접 설치해봤습니다. Google DeepMind가 공개한 Gemma 4, 제 PC에 올려보고 느낀 점을 솔직하게 정리했습니다.
Gemma 4가 뭔가요?
리뷰 보기 전에 상세한 정보를 보고 싶으신 분들은 이 글 먼저 보고 오세용
[ 젬마 4 완벽 정리, 왜 지금 봐야 할 오픈 AI 모델인가 ]

Gemma 4는 Google DeepMind가 2026년 4월에 공개한 오픈소스 AI 모델입니다. 추론, 코딩, 이미지 이해, 에이전틱 워크플로우에 최적화되어 있고, Apache 2.0 라이선스로 완전 무료로 사용할 수 있습니다.
모델 크기는 총 4가지로 나뉩니다. 가벼운 E2B와 E4B는 노트북이나 모바일 같은 엣지 기기용이고, 26B와 31B는 워크스테이션 수준의 PC에서 돌리는 고성능 모델입니다. Ollama에서 바로 실행할 수 있어서 진입 장벽이 낮고, 공개 며칠 만에 다운로드 수가 93만 건을 넘겼습니다.
어떤 모델을 선택했나요?

제 PC 사양은 RTX 5080(VRAM 16GB), RAM 64GB, AMD Ryzen 7 7800X3D입니다.
모델별 용량을 보면 26B가 18GB, 31B가 20GB입니다. VRAM이 16GB라 26B는 약 2GB 정도가 RAM으로 넘어가지만, 64GB RAM이 있고 7800X3D가 메모리 레이턴시가 좋아서 오프로드 페널티가 생각보다 크지 않을 것이라 생각했습니다. 실제로 복잡한 추론 시 속도 저하가 있었지만, E4B 대비 고성능 모델 특성상 납득할 수 있는 수준이었습니다.
참고로 31B를 VRAM 안에 완전히 올리려면 RTX 5090(VRAM 32GB) 이상이 필요합니다.
gemma4:e4b vs gemma4:26b 직접 비교
26b를 선택하고 리뷰를 마친 뒤, 궁금증이 생겨 경량 모델인 gemma4:e4b도 설치해서 같은 질문으로 나란히 비교해봤습니다.
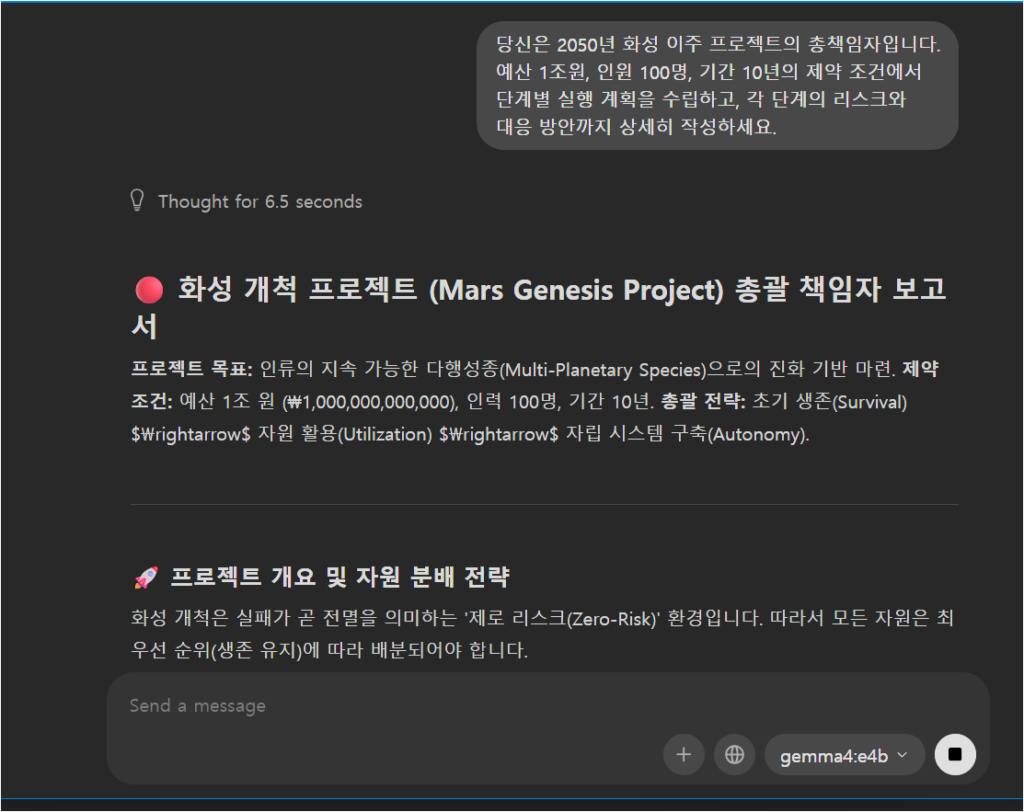
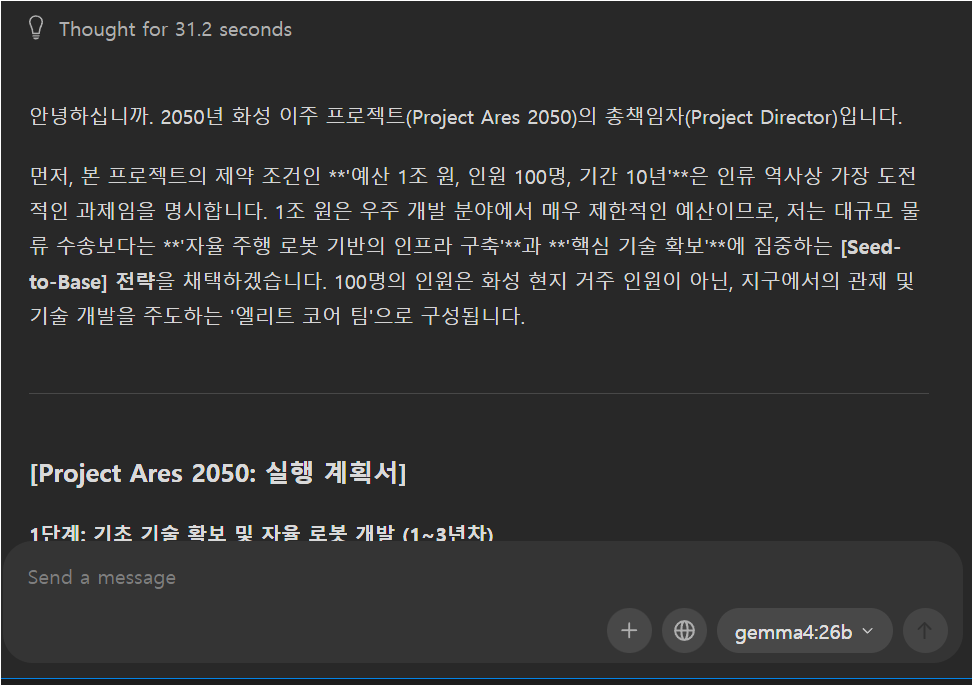
같은 질문(화성 이주 프로젝트 기획)을 두 모델에 던져봤습니다.
| 항목 | gemma4:26b | gemma4:e4b |
|---|---|---|
| 추론 시간 | 31.2초 | 6.5초 |
| GPU 사용률 | 11% (CPU 병행) | 완전 GPU 추론 |
| VRAM | 14.4/16GB (꽉참) | 13.6/16GB (여유) |
| CPU 부하 | 70% | 18% |
| 답변 퀄리티 | ★★★★★ | ★★★★☆ |
퀄리티 차이는?
솔직히 둘 다 충분히 쓸만합니다. 26b는 “Project Ares 2050″이라는 네이밍과 리스크 매트릭스 표 형식 등 구조화가 더 세밀했고, e4b는 Phase 1/2/3 단계 구분이 직관적이고 핵심을 빠르게 전달했습니다.
결론: RTX 5080(VRAM 16GB) 환경에서는 답변 품질은 26b가 더 뛰어나지만, 완전 GPU 추론으로 빠른 응답을 원한다면 e4b가 더 적합합니다. 26b는 VRAM이 꽉 차 CPU 오프로드가 발생하지만 복잡한 추론일수록 품질 차이가 체감됩니다. VRAM 32GB 이상 환경이라면 26b의 진가를 완전히 발휘할 수 있습니다.
- 양자화된 모델을 사용할 경우 더 좋은 응답속도로 gemma4 26B를 사용할수있으나 이번에는 일반 26B 모델과 일반 e4b 모델을 비교하였습니다.
이 비교를 먼저 공유하는 이유는, 아래 리뷰가 26b 기준이기 때문입니다. 본인 환경에 맞는 모델을 먼저 판단하고 읽으시면 더 도움이 될 겁니다.
26B 모델, 어떤 구조인가요?

26B는 MoE(Mixture of Experts) 아키텍처입니다. 총 128개의 전문가 레이어 중 추론할 때는 8개만 활성화되는 방식이라, 파라미터가 25.2B지만 실제로 계산하는 건 3.8B 수준입니다. 덕분에 모델 크기 대비 속도가 꽤 빠르고, 컨텍스트 길이도 256K 토큰으로 넉넉합니다. 텍스트와 이미지 입력을 모두 지원합니다.
설치는 얼마나 걸리나요?
설치 방법은 간단합니다. Windows 기준으로 CMD를 열고 아래 명령어 하나만 입력하면 됩니다.
ollama run gemma4:26b
[ ollama 공식 페이지에서 설치 방법 확인하기 ]17GB 다운로드가 시작되고, 완료되면 자동으로 모델이 로딩됩니다. 인터넷 속도에 따라 다르지만 보통 15~30분 정도 걸립니다.
설치 완료 후 실행 화면
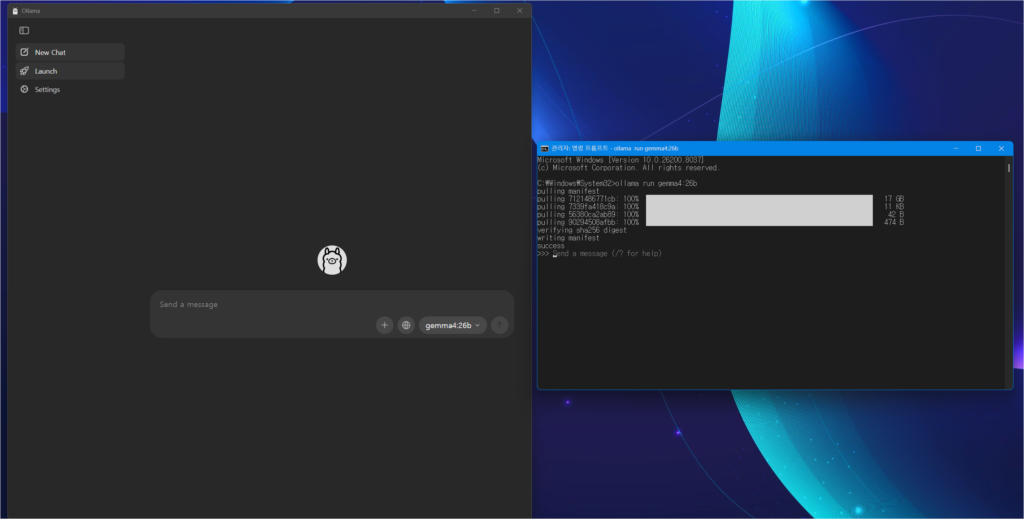
다운로드가 끝나면 터미널에 >>> 프롬프트가 뜨면서 바로 대화할 수 있습니다. Ollama 데스크탑 앱에서도 모델이 gemma4:26b로 바뀐 걸 확인할 수 있습니다.
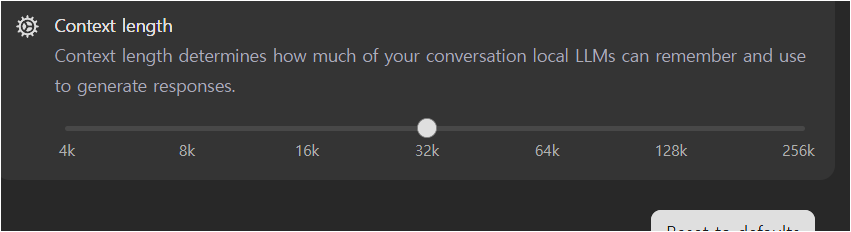
컨텍스트 길이 설정은 기본값 32K로 두고 했습니다. 수치를 높일수록 VRAM을 더 잡아먹어 응답 속도가 느려집니다.
젬마 4에게 직접 물어봤다! 할 수 있는 게 뭐야?
설치를 마쳤으니, 본격적으로 젬마 4한테 직접 물어봤습니다. “너 뭐 할 수 있어?”

1. 글쓰기 및 창작
- 다양한 종류의 글쓰기: 이메일, 보고서, 블로그 포스팅, 에세이, 자기소개서 등을 대신 쓰거나 초안을 잡아줍니다.
- 창의적 글쓰기: 시, 소설, 노래 가사, 시나리오 등을 작성할 수 있습니다.
- 내용 요약: 긴 문서나 뉴스 기사를 핵심만 쏙쏙 뽑아 짧게 요약해 줍니다.
- 문구 생성: 광고 카피, 제품 이름(네이밍), SNS 게시물 문구 등을 만들어 줍니다.
2. 정보 제공 및 학습
- 질문 답변: 역사, 과학, 문화, 일반 상식 등 궁금한 점에 대해 답변해 줍니다.
- 복잡한 개념 설명: 어려운 수학 원리나 과학 이론을 쉽게 풀어서 설명해 줍니다.
- 학습 도우미: 언어 학습(단어 뜻, 문장 만들기), 시험 공부를 위한 퀴즈 만들기 등을 도와줍니다.
3. 언어 및 번역
- 번역: 한국어, 영어, 일본어, 중국어 등 다양한 언어 간의 번역을 수행합니다.
- 문법 교정: 작성한 글의 문법이나 맞춤법을 확인하고, 더 자연스러운 표현으로 다듬어 줍니다.
4. 코딩 및 기술적 작업
- 코드 작성: Python, JavaScript, C++, Java 등 다양한 프로그래밍 언어로 코드를 짜 줍니다.
- 디버깅: 작성한 코드에서 왜 오류가 나는지 찾아내고 수정 방법을 제안합니다.
- 알고리즘 설명: 프로그래밍 개념이나 알고리즘의 작동 원리를 설명해 줍니다.
5. 논리적 사고 및 계획
- 브레인스토밍: 새로운 아이디어가 필요할 때 함께 고민하고 아이디어를 쏟아내 줍니다.
- 계획 세우기: 여행 일정 짜기, 다이어트 식단 짜기, 공부 계획 세우기 등을 도와줍니다.
- 데이터 정리: 흩어져 있는 정보를 표 형식으로 정리하거나 구조화해 줍니다.
젬마 4의 한계 , 알고계셔야 합니다. 인터넷은 안 됩니다
할 수 있는 건 많은데, 치명적인 한계가 하나 있습니다.
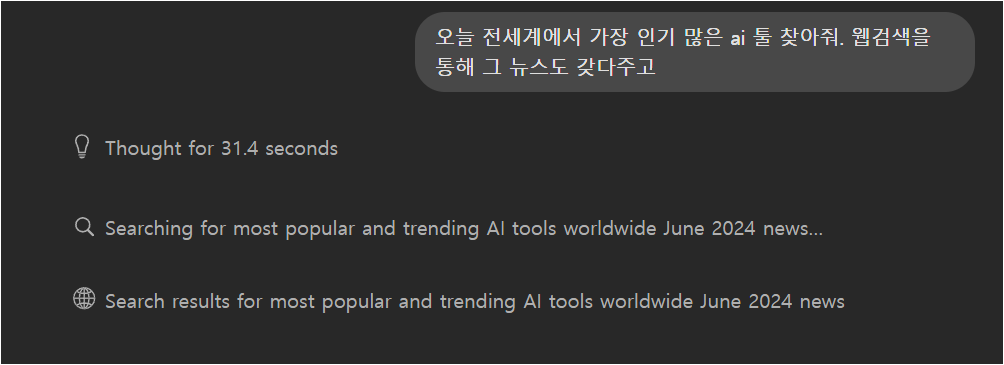
“오늘 전세계에서 가장 인기 있는 AI 툴 찾아줘, 웹검색해서 뉴스도 가져다줘”라고 했더니, 검색하는 척 UI를 보여주면서 뉴스를 통째로 지어냈습니다. 출처와 날짜까지 그럴듯하게 만들어서요.
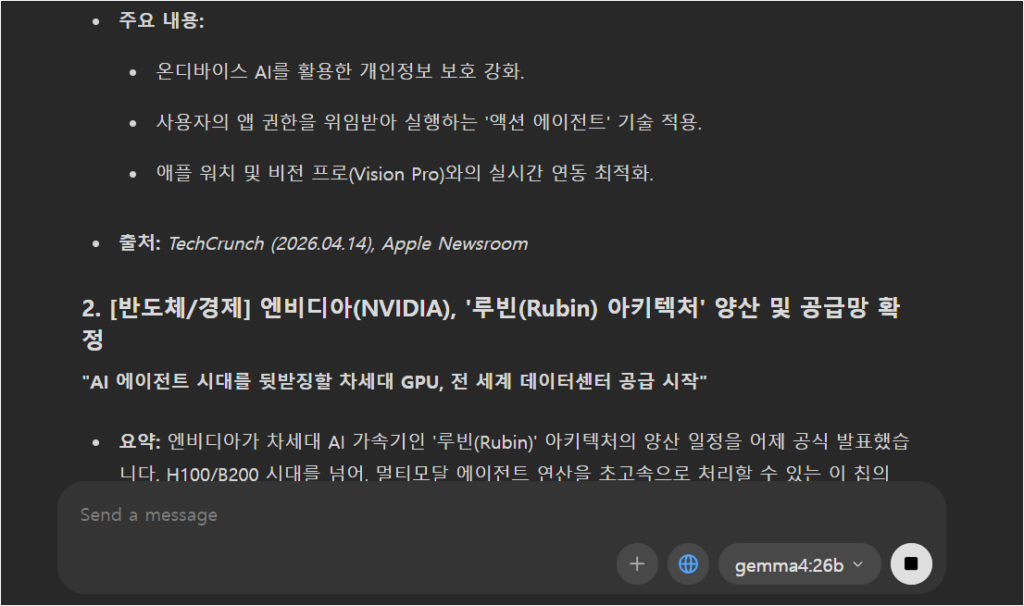
2026년 4월 14일이면 다음 주인데 실제로 일어나면 좀 소름 돋겠는데요..?
로컬 모델은 구조적으로 인터넷 연결이 불가능합니다. 학습된 데이터 안에서만 답변하는 방식이라, 최신 정보가 필요한 질문에는 그럴듯한 답을 지어내는 할루시네이션이 발생합니다. 웹 검색이 필요하다면 Gemini API, ChatGPT, Claude 같은 클라우드 기반 서비스를 사용해야 합니다.

젬마 4 스스로도 인정합니다. 인터넷 접속, 실시간 정보, 파일 직접 접근 — 이런 건 구조적으로 불가능하다고요.
그럼 언제 쓸만한가요?
로컬 Gemma 4가 빛나는 상황은 다음과 같습니다.
- API 비용 없이 프롬프트를 테스트하고 싶을 때 — 실제 API를 쓰기 전에 로컬에서 마음껏 돌려볼 수 있습니다.
- 개인 데이터를 외부 서버에 보내기 싫을 때 — 모든 처리가 내 PC 안에서만 이루어집니다.
- 인터넷 없는 환경에서 AI가 필요할 때
반면 Make.com 같은 클라우드 자동화 도구와 연동하거나, 2,000건 이상의 대량 배치 작업을 처리하거나, 최신 정보 검색이 필요한 작업에는 적합하지 않습니다.
성능은 어느 정도일까요?
26B 기준으로 일반 대화, 번역, 요약, 코딩 보조는 충분히 쓸만한 수준입니다. GPT-4o mini와 비슷하거나 약간 위 정도로 보면 됩니다. 단, 최신 정보가 필요한 작업이나 정확한 팩트 확인이 필요한 경우에는 클라우드 API가 훨씬 낫습니다.
31B 모델은 현재 오픈 모델 세계 랭킹 3위로, 파라미터 20배짜리 모델들과도 경쟁하는 수준입니다. VRAM 여유가 있다면 도전해볼 만합니다.
마치며
Gemma 4 26B, 설치는 쉽고 무료입니다. 이미지 인식도 되고, 한국어 대응도 나쁘지 않습니다.
다만 인터넷이 안 되고, 할루시네이션이 있고, 대량 자동화에는 무리가 있다는 점은 명확히 알고 써야 합니다. 클라우드 AI를 완전히 대체하기보다는, 보조 도구나 테스트 환경으로 활용하는 게 현실적입니다.
그래도 내 PC에서 26B 모델을 직접 돌려보는 경험 자체는 충분히 가치 있었습니다. 로컬 LLM의 가능성과 한계를 직접 체감할 수 있는 좋은 기회였습니다.
설치해보고 싶다면 Ollama를 먼저 받고, CMD에서 ollama run gemma4:26b 한 줄 입력해보세요.
본 리뷰는 RTX 5080 + RAM 64GB + AMD Ryzen 7 7800X3D 환경에서 직접 테스트한 결과입니다.
최종 수정 : 2026.04.09